Binning data
Using scipy.stats:
from scipy.stats import binned_statistic
x = np.random.random(size=500)
y = np.random.normal(size=500)
bins = np.linspace(0, 1, 10)
x_mean = binned_statistic(x, x, statistic=np.mean, bins=bins).statistic
x_std = binned_statistic(x, x, statistic=np.std, bins=bins).statistic
y_mean = binned_statistic(x, y, statistic=np.mean, bins=bins).statistic
y_std = binned_statistic(x, y, statistic=np.std, bins=bins).statistic
If working with 2D data one can use binned_statistic_2d:
from scipy.stats import binned_statistic_2d
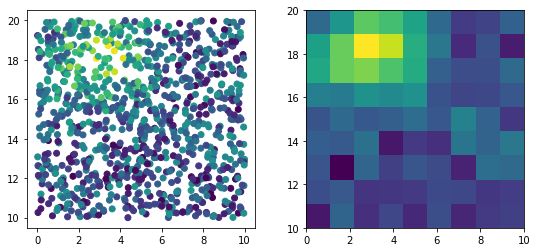
x = np.random.uniform(0, 10, 1000)
y = np.random.uniform(10, 20, 1000)
z = np.exp(-(x-3)**2/5 - (y-18)**2/5) + np.random.random(1000)
x_bins = np.linspace(0, 10, 10)
y_bins = np.linspace(10, 20, 10)
ret = binned_statistic_2d(x, y, z, statistic=np.mean, bins=[x_bins, y_bins])
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(9, 4))
ax0.scatter(x, y, c=z)
ax1.imshow(ret.statistic.T, origin='bottom', extent=(0, 10, 10, 20))
Old method
Possible way to bin data using numpy digitize function:
def bin_data(data_x, data_y, bins):
digitized = np.digitize(data_x, bins)
x = np.array([data_x[digitized == i].mean() for i in range(1, len(bins)) if i in digitized])
x_err = np.array([data_x[digitized == i].std() for i in range(1, len(bins)) if i in digitized])
y = [data_y[digitized == i].mean() for i in range(1, len(bins)) if i in digitized]
y_err = np.array([data_y[digitized == i].std() for i in range(1, len(bins)) if i in digitized])
return x, y, x_err, y_err
Example:
import numpy as np
import matplotlib.pyplot as plt
x = np.random.random(size=500)
y = np.random.normal(size=500)
bins = np.linspace(0, 1, 10)
plt.scatter(x, y, color='grey', s=5)
x_bin, y_bin, x_err, y_err = bin_data(x, y, bins)
plt.errorbar(x_bin, y_bin, yerr= y_err, xerr=x_err, fmt='H', ms=10, color='black')